
比肩 GPT-5 的 Kernel Coding 模型!Dr. Kernel 用多轮 RL 训练大模型 GPU Kernel 生成
让大模型通过强化学习(RL)生成 GPU Kernel 是业界共同的期望。但由于极易受“钻漏洞(reward hacking)”和“惰性优化(lazy optimization)”等长程训练不稳定问题的干扰,一直缺乏系统化方案 。
.png?width=800)
来自港科大、字节跳动、港中深和南洋理工的研究者们提出了Dr. Kernel,一套包含稳定、可大规模并行的分布式 GPU环境和创新 RL训练算法的解决方案,使得大模型在Kernel生成上的RL真正可行。
论文:Dr. Kernel: Reinforcement Learning Done Right for Triton Kernel Generations
链接:https://arxiv.org/abs/2602.05885
代码:https://github.com/hkust-nlp/KernelGYM

3月7日(周六)上午10点,青稞社区和减论平台将联合组织青稞Talk 第110期,香港科技大学(HKUST)在读博士刘威,将直播分享《Dr. Kernel:突破大模型 GPU Kernel 生成的多轮 RL 训练瓶颈》。
本次分享将探讨如何突破大模型利用强化学习生成 GPU Kernel 的训练瓶颈,介绍Dr. Kernel 解决方案 。
该方案从构建稳定的大规模并行分布式 GPU 环境出发,并提出创新的多轮 RL 算法,使得大模型在 Kernel 生成上的长期 RL 训练真正可行 。
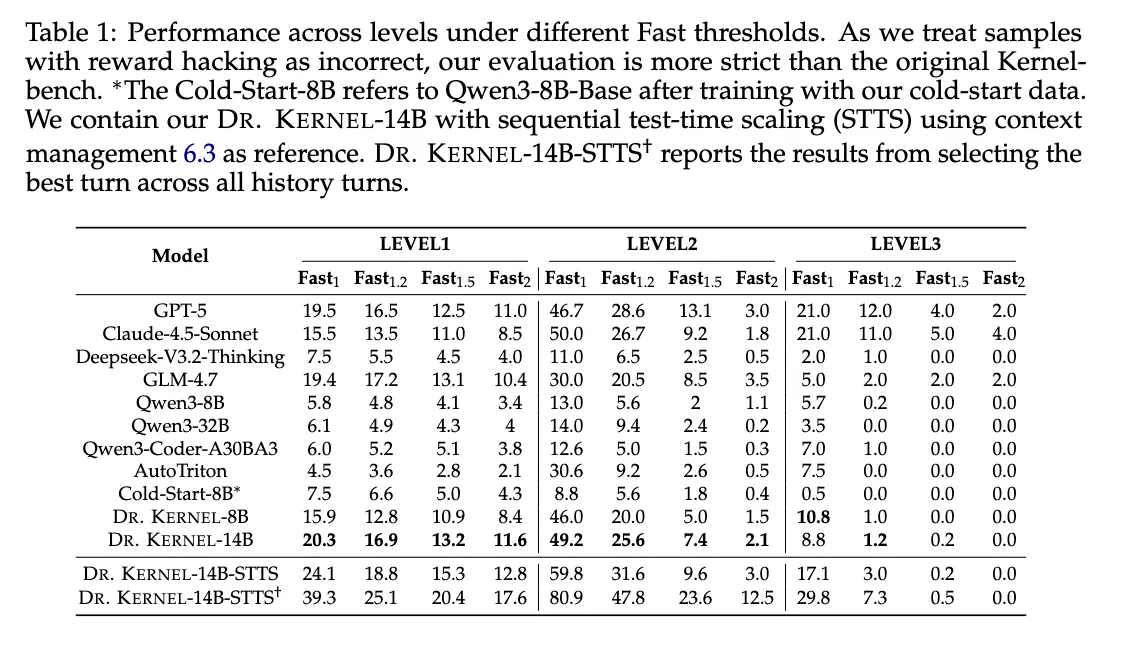
最终得到的 Dr. Kernel-14B 模型在结合序列测试时扩展(STTS)后,于 KernelBench 的 Level-2 子集中实现了 47.8% 的有效提速代码(相对参考实现至少快 1.2 倍)生成比例,成功超越了前沿模型例如 GPT-5 与 Claude-4.5-Sonnet 。
分享嘉宾
刘威,香港科技大学(HKUST)在读博士生,导师是何俊贤教授。他的研究方向致力于开发具有理论基础且可扩展的方法,旨在构建能够与复杂真实环境互动的模型。近期,他的研究重点涵盖了强化学习(包括 M-STaR, LASER, SimpleRL, Dr. Kernel 等项目)、可扩展合成数据(Deita)以及智能体系统(Toolathlon)和测试时训练。他已在 ICLR、ICML、ACL 等顶级机器学习与自然语言处理会议上发表论文 10 余篇,总被引次数超过 1,000 次,其开源项目在 GitHub 上获得超过 4,000 Stars。
主题提纲
Dr. Kernel:突破大模型 GPU Kernel 生成的多轮 RL 训练瓶颈
1、Kernel 代码生成的背景与核心挑战
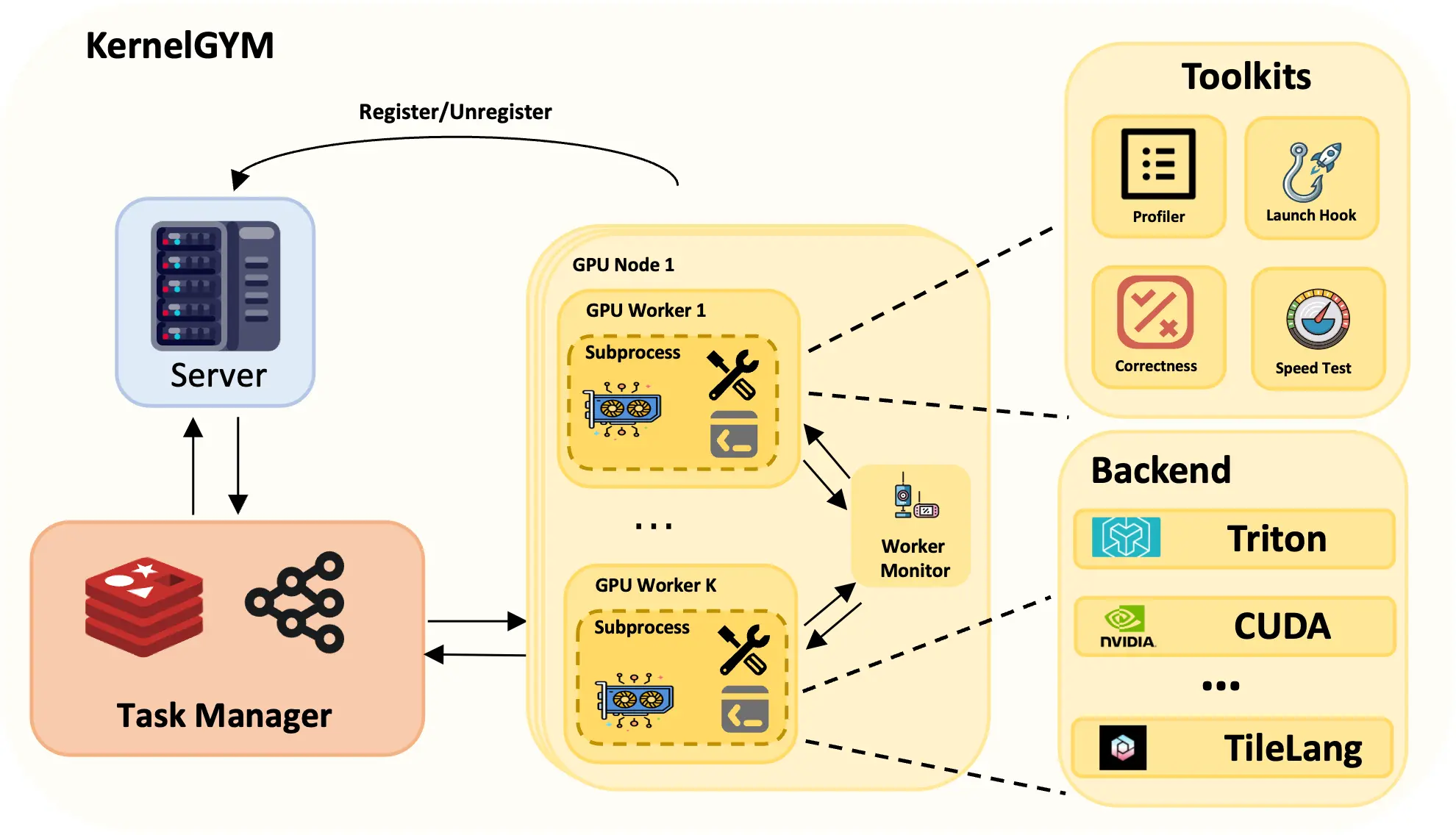
2、KernelGYM: 为 Kernel RL 打造的开源、分布式 GPU RL 环境
3、TRLOO 解决 GRPO 的 Self-inclusion 偏差,实现无偏多轮 RL
4、从缓解训推不一致 (MRS) 到对齐优化目标 (PR/PRS) 改善模型行为
5、未来方向 & AMA (Ask Me Anything)
直播时间
3月7日(周六)10:00 - 11:00