
大模型因 Data Scaling 屡创新高,但在自动驾驶却失灵了——现实世界难以提供足够的关键与长尾场景,采集到的大多是价值有限的常态片段,导致数据越多、提升越难。
因此,自动驾驶的瓶颈不在规模,而在缺乏能系统生成关键场景并支撑大规模训练的新路径。
为此,来自香港大学OpenDriveLab、中科院自动化所、小米汽车的联合团队提出了一种解决方案——SimScale, 通过真实世界仿真生成关键场景,以及真实仿真协同训练策略,首次揭示了自动驾驶仿真数据的规模效应:无需更多真实数据,只靠扩大仿真数量,就能持续突破任何端到端驾驶模型的性能上限!
SimScale 被 CVPR 2026 接收并被评选为 Oral Presentation.

Github: https://github.com/OpenDriveLab/SimScale
Home: https://opendrivelab.com/SimScale/
ArXiv:https://arxiv.org/abs/2511.23369
代码、仿真数据、模型权重已经全面开源!欢迎大家讨论、引用、Star🌟
🤖什么是SimScale

• 一个能“无限扩张世界”的仿真生成框架:通过高保真神经渲染,自动制造多样化反应式交通场景与伪专家示范。
• 一套让仿真与真实“相互增益”的训练策略,使各种端到端模型都能越训越强,鲁棒性与泛化性全面提升。
• 一份首次系统揭示自动驾驶仿真规模效益的“实践手册”,通过实验深度分析把仿真推向规模化的关键因素。
可扩展仿真生成框架,探索未见
可用于端到端模型训练的仿真数据需要同时包含合成图像和专家示范轨迹,以确保这些场景能“教得动模型”。因此SimScale采用“干扰-规划”的策略,实现规模化的仿真数据生成。
高保真神经渲染引擎
基于3D高斯泼溅(3DGS)重建的真实场景资产,SimScale 能将车辆在不同位置和朝向下的状态渲染成多视角 RGB 视频。
系统通过将背景与动态车辆分别建模并剔除低质量区域,在保持高效渲染的同时最大程度保留真实世界的光照、几何和语义细节。

轨迹扰动与状态探索
为了覆盖长尾关键场景,SimScale 在真实轨迹上施加合理范围的扰动,并借助空间下采样去除冗余,最后生成多样状态分布。
这些操作会让自车进入现实中难以遇见的危险情形,如偏离车道、逼近障碍物或激进交互,从而系统性扩展策略的可见状态空间,提供人驾数据中无法安全采集的数据。
伪专家轨迹示范生成
在扰动合成出的复杂与失稳状态中,仿真需要为模型提供高质量的监督示范。SimScale 设计了两类互补的伪专家策略(Pseudo-Expert) ,便于后续能够在鲁棒恢复与策略探索之间进行探索:
1、基于恢复的策略(Recovery-based) 以安全与稳定为优先目标,偏保守。该策略根据车辆的失稳状态快速生成一条可控、平顺、能将车辆拉回人类轨迹的恢复路径,为模型提供可靠的“安全底线”示范。
2、基于规划的策略(Planner-based) 依托具有特权信息的规划器,它会选择更灵活、探索性更强的行为,如提前变道或主动避让,使模型能够学习更高价值、更接近真实驾驶决策的复杂规划模式。
反馈式多样场景模拟
SimScale 不仅模拟自车,还让周围交通参与者具备反应能力,包括让其他车辆根据自车行为触发减速、避让、跟车、切入等真实道路中的互动策略。
这种反应式交通模型避免了“单向度”仿真,使场景能自然演化出更多复杂动态,从而形成更接近真实驾驶的可扩展场景分布。
仿真-真实协同训练,互为增益
SimScale 不仅能大规模生成关键场景,还提供了一套 仿真-真实数据协同训练 的策略(Sim-Real Co-training),让端到端自动驾驶模型充分利用仿真数据,同时保持对人类驾驶行为的忠实拟合。
仿真-真实协同训练策略
在训练过程中,SimScale 从真实数据集和仿真生成数据集中随机抽样,使模型既保留真实驾驶分布,又避免因渲染细微差异、光照或动态抖动等仿真瑕疵导致性能下降。
借助完全自动化的可扩展仿真生成框架,SimScale 可以逐步增加新仿真样本,无需额外真实数据即可不断扩展训练数据规模。
支持任意端到端规划模型
SimScale 的协同训练策略可适用于各类端到端规划模型,包括回归型(regression-based)、扩散型(diffusion-based)及轨迹评分型(scoring-based)规划器。
对于依赖专家示范轨迹的规划器,仿真伪专家轨迹可以提供可靠监督;
而对于奖励驱动的规划器(如轨迹评分型),仿真数据可直接用于优化策略,无需单一路径示范,让模型探索最优策略,实现仿真数据利用效率最大化。
任意端到端驾驶模型,全面提升
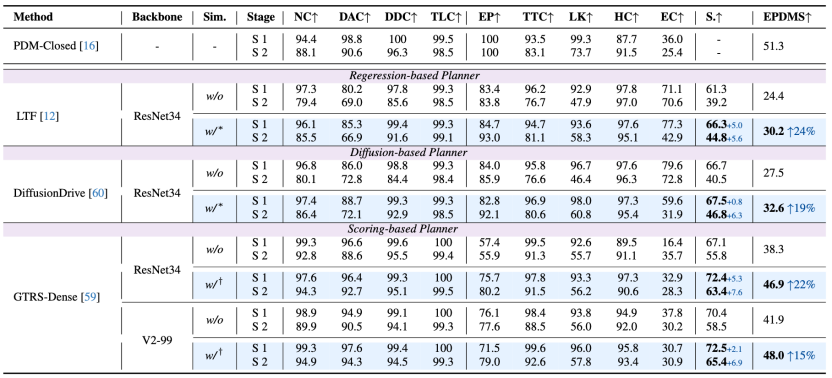
真实世界测评中的鲁棒性和泛化性是自动驾驶模型的关键能力,前者决定了模型的上限,反映了模型在未见的极端场景下的应对能力(navhard基准);后者决定了模型的下限,反映了模型在多样化挑战性场景下的可靠性(navtest基准)。
然而传统训练范式很难在两者之间做到平衡,但经过全面的测试,SimScale仿真-真实协同训练在真实世界闭环测评中,实现了鲁棒性与泛化性的全面提升!
navhard基准
所有类型的端到端规划器的性能均有大幅增强,最多可提升 8.6 EPDMS,其中基础性能较弱的规划器更增加了超过20%的性能!
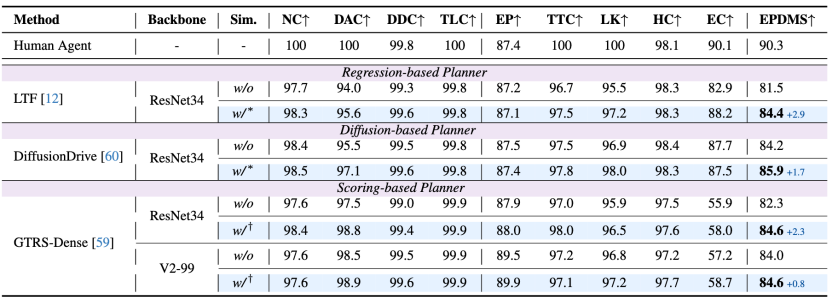
navtest基准
所有类型的端到端规划器的性能也有明显增强,最多可提升2.9 EPDMS.
NAVSIMv2 官方排行榜 # 1
通过对轨迹评分规划器进行多专家集成 (Multi-Expert Ensemble),SimScale实现了NAVSIMv2官方排行榜 #1,这也揭示了不同伪专家训练的模型存在潜在的互补能力,可以实现彼此增益。

揭秘仿真数据的规模效应

SimScale 首次系统揭示了仿真数据对端到端规划模型性能的规模效应,通过拟合对数二次函数,建模总数据量(真实 + 仿真)与模型表现的关系,展示了在真实数据固定时,随着仿真数据量增加,模型在不同伪专家策略和规划器上的表现差异。
探索性伪专家更高效
恢复型伪专家性能提升较早收敛,最终表现不如规划型。原因在于恢复型始终贴近人类轨迹,缺乏多样性;规划型可探索更广状态空间,生成更多可行解,从而充分发挥仿真数据价值。
多模态建模激发数据扩展潜力
多峰行为分布是自动驾驶的本质问题,回归型模型难以应对多样化仿真示范,而扩散型模型能捕捉多模态特性,随数据增加表现持续提升。
奖励驱动即可高效训练
对评分型规划器,仅使用奖励信号即可在仿真中取得优异表现,无需伪专家轨迹。这说明奖励引导能充分发挥仿真数据的价值,同时保持策略优化方向稳定

为了验证 SimScale 在实际端到端训练中的价值,我们固定真实-仿真数据比例,系统研究了当真实数据扩增,仿真数据是否还能持续带来收益.
仿真增益随真实数据规模持续稳定
无论真实数据是稀缺还是丰富,仿真数据带来的性能提升始终显著且不减弱:在小数据量下提升最为明显,而当真实数据扩增后,增益依旧保持稳定,没有出现常见的“收益饱和”。这表明 SimScale 能在不同数据规模下持续放大端到端系统的性能。
仿真场景数据可视化展示

仿真中生成四类真实驾驶中最易触发模型失效的关键场景,包括偏离车道、近距离失碰、车道脱出与加塞切入,并为每个场景提供伪专家轨迹与扰动历史动作,帮助策略在高风险、短时决策条件下学习更强的纠偏与避险能力。



模拟自车状态和轨迹呈现出明显的差异和更多样化的分布。
总结
SimScale通过创新性的真实世界仿真架构与虚实协同训练策略,全面提升任意端到端驾驶模型的鲁棒性和泛化性;
首次揭示了自动驾驶仿真数据的规模效应:无需更多真实数据,只靠扩大仿真数量,就能持续突破任何端到端驾驶模型的性能上限!
4月21日(周二)晚8点,#青稞Talk 第121期,港大OpenDriveLab和小米具身团队实习生、中科院自动化所模式识别实验室博士生田浩辰,将直播分享《SimScale:大规模真实世界仿真重塑端到端自动驾驶学习范式》。
分享嘉宾
田浩辰,中科院自动化所模式识别实验室在读博士生,师从谭铁牛院士,港大OpenDriveLab和小米具身团队实习生。研究方向为端到端具身智能系统,多模态大模型。他在CVPR, ICLR, ICML, TPAMI等人工智能顶会和期刊发表过多篇论文,其中关于端到端自动驾驶的文章获得 CVPR 26 Oral.
主题提纲
SimScale:大规模真实世界仿真重塑端到端自动驾驶学习范式
1、自动驾驶的 Data Scaling 瓶颈
2、SimScale:可扩展仿真生成框架
3、仿真-真实数据协同训练策略
4、仿真数据的规模效应
5、AMA(Ask Me Anything)环节
直播时间
4月21日(周二)20:00 - 21:00