在 LLM 强化学习(RL)的训练中,有一个长期困扰算法工程师的“幽灵”:训练-推理不一致(Training-Inference Mismatch) 。很多时候,你会发现训练开始阶段一切正常,但是一段时间后训练引擎和推理引擎生成token的概率分布就有可能越来越远,accuracy断崖式下跌。
主流的观点往往将其归咎于工程实现:比如BF16/FP32 转换引入舍入误差,以及训练/推理引擎计算顺序不同(有限精度下浮点数的运算并不满足结合律)。然而,今天分享的研究提出了不同的观察:这更像是一个动态优化问题,而非单纯的工程精度问题。
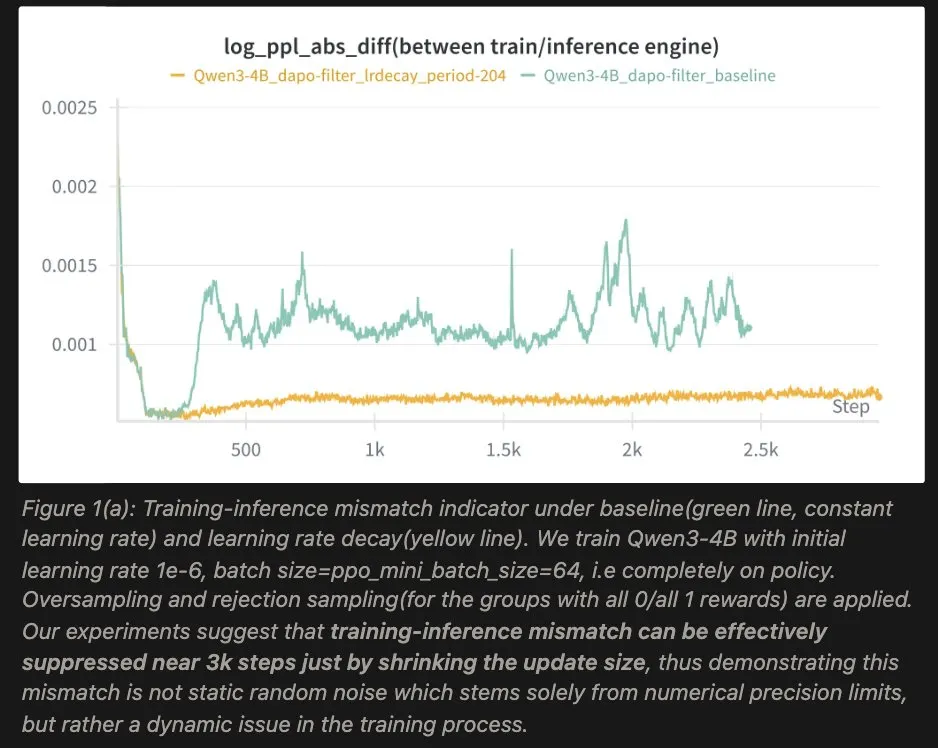
1.核心观察:梯度噪声的动态演变
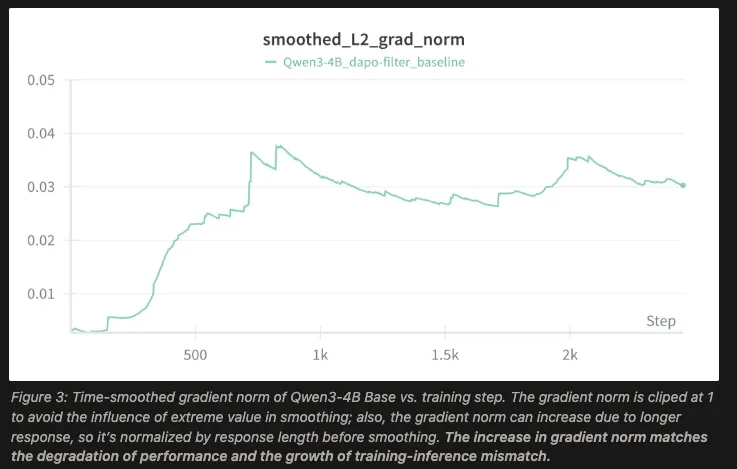
研究团队通过监测训练过程中的梯度范数(Gradient Norm),并将其拆解为信号与噪声两部分,观察到了以下动态过程:
- 信号衰减与噪声增长: 在针对固定数据集的学习过程中,随着有效信息的提取,梯度中的信号强度理应逐渐下降。
- 噪声主导: 与此同时,梯度总范数却仍然增长,这很可能是来源于噪声。
当这种上升的噪声主导了参数更新的方向时,模型会被推向参数空间中的不稳定区域。在这些区域,训练环境与推理环境的微小差异可能会被放大,从而加剧了“训练-推理不一致”。
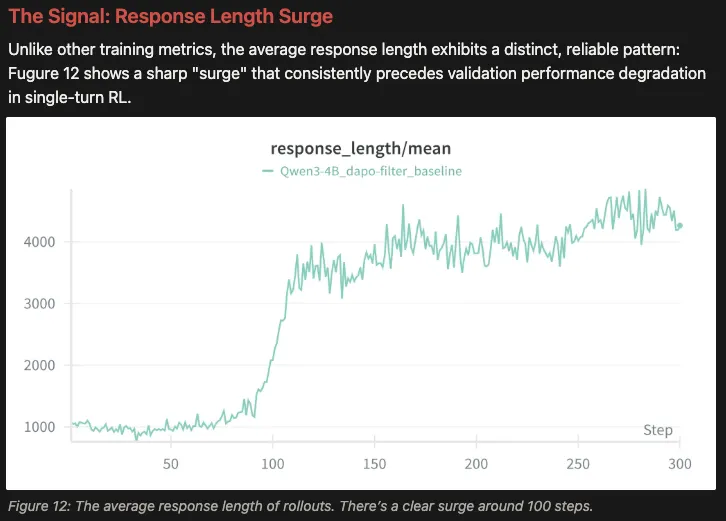
2.预警信号:回复长度(Response Length)的代理作用
为什么梯度噪声会突然失控?研究指出这与模型生成的 回复长度(Response Length) 高度相关。
在强化学习中,随着训练推进,模型生成的轨迹(Trajectories)往往会变长。从统计学角度看,更长的轨迹意味着策略梯度(Policy Gradients)具有更高的方差。
实验数据表明,模型的训练崩溃通常发生在在一个明显的“回复长度激增”现象之后。因此,回复长度可以被视为监控梯度噪声是否可控的一个有效代理指标(Proxy)。
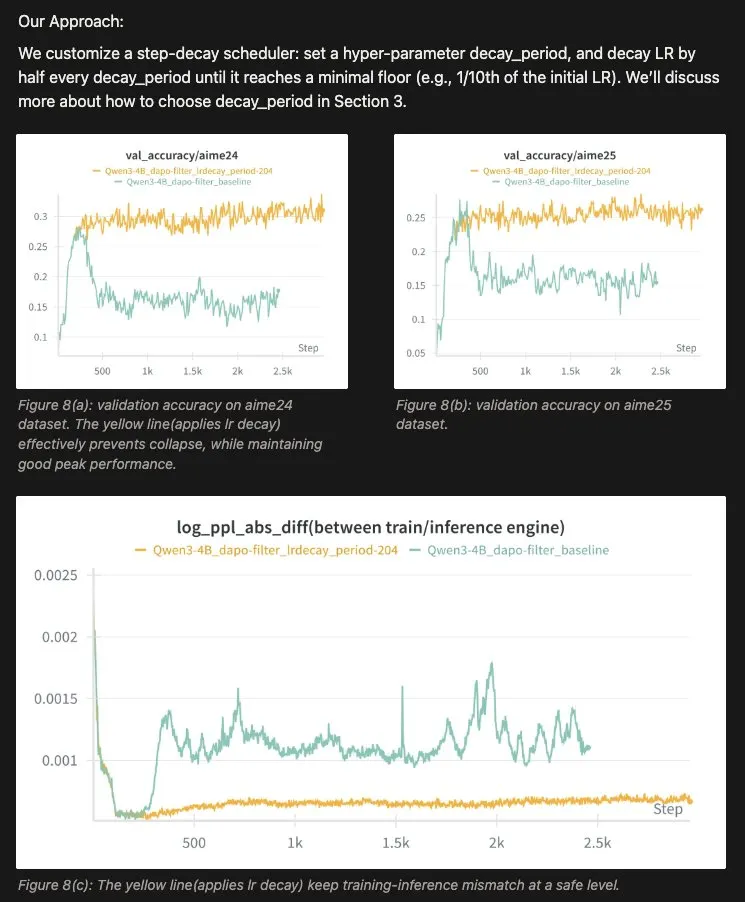
3.解决方案:基于长度触发的自适应步进衰减
传统的余弦衰减(Cosine decay)由于其预设的时间窗口无法根据实时的训练情况来调整学习率。因此,作者提出了一种自适应步进衰减(Adaptive Step-Decay)方案,核心逻辑如下:
- 触发机制: 实时监控回复长度,当长度激增发生后一段时间(1.8x),学习率(LR)减半。
- 数学依据: 训练的有效进展与学习率 \eta 呈线性关系 O(\eta),而噪声带来的惩罚则与 \eta^2 呈平方关系。
这意味着,通过降低学习率,可以在保留大部分学习进度的同时,以更快的速度压制梯度噪声,从而将优化轨迹拉回稳定区域。
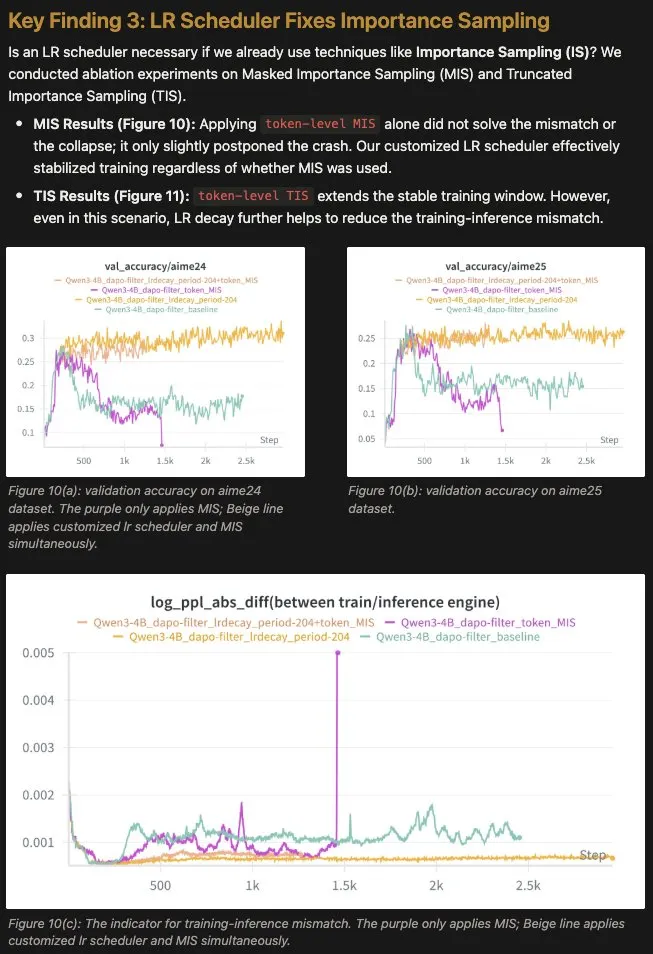
4.关于重要性采样(IS)的讨论
在处理 Off-policy 漂移时,重要性采样(Importance Sampling)是常用的数学修正手段。但消融实验显示:
- 单纯依靠 IS: 训练崩溃仍有可能发生。
- 结合 LR 调度: 无论是否使用 IS,调整学习率都能显著稳定训练。
结论与建议
这篇文章为 LLM 强化学习的稳定性优化提供了务实的参考:
- 识别本质: 将 Mismatch 视为一个受优化动力学驱动的动态梯度噪声问题。
- 动态调整策略: 当观测到长度激增信号时,及时采取学习率衰减措施,以提升长期的训练稳定性。
论文原址:
Beyond Precision: Why Training-Inference Mismatch is an Optimization Problem and How Simple LR Scheduling Fixes It
🔗https://richardli.xyz/mismatch-lr-schedule
如果您在训练 PPO 或 GRPO 时也遇到了类似的崩溃问题,欢迎在评论区分享您的观察和解决思路。